コラム◆IT散歩/第9回:「“亥 = 0x88E5”、文字コードの世界」(前編)
前回は干支の話をした。
2019年の「亥(いのしし)」は、子、丑、寅、卯・・・・と数えて12番目。
十二支のビリっけつ。
・イノシシはなぜビリか?

イノシシはなぜ“ビリ”なのか。十二支を動物に例える話の中で、これにもいくつかの物語がある。
国の最高神が、それぞれの動物の名前で年を数えることとし、会合を招集した。そして、その順序は神の元に着いた順とすると通達した。
しかし、神の元に着くには大きな川を渡らねばならなかった。
ネズミと猫は雄牛の背に乗って川を渡っていたが、ネズミは猫が水が苦手なのを知っていたので、途中で猫を川へ突き落とした。その恨みがあるので、猫は今もネズミを追いかけている。
雄牛が対岸に着いた途端、ネズミは飛び降りて最初に到着、2番目が雄牛。
次はトラが川を泳ぎきった。ウサギは石伝いに飛び跳ねて、途中で丸太に飛び乗った。そして、龍は5番目。神が龍に「どうして早く飛んでこなかったのか?」と尋ねると、「すべての人々と生物を助けるため、雨を止めなければいけなかったので遅れた」と言った。丸太に乗ったウサギを対岸に送るため、風を起こして先にやってもいた。ウサギは龍に助けられ4番目。
馬が駆けつけ、ヘビは馬の蹄に隠れていたため、馬が気付き驚いて後ずさりしたので、ヘビが先、馬が後。羊とサルと雄鶏は助け合いながら一緒にきた。神は助け合ってきたことを喜び、羊、サル、雄鶏と、8番目、9番目、10番目とした。
犬は泳ぎがうまいが、水の中で遊んでいたため11番目。最後のブタ(*中国ではブタ、日本はイノシシ)は、居眠りをしていて、気付いたら最後だった。
(中国の民間伝承)
また、イノシシは勢いあまって神の前を通り過ぎてしまい、最後になったという話もある。
*ブタは元々イノシシを家畜化したもの。
干支が伝わった際、日本ではその慣習がなく、一方で森林が豊富でイノシシがたくさん獲れたためのよう。
こうした童話のような話が、今も日本の年を数える大元になっている。ギスギスした、論理だけでこの社会は成り立っていない点で心休まる。
さて、本題に・・・
・文字コードと字体、字形
タイトルに “亥=0x88E5” と表記した。
“0x” は16進数であることの目印であり、「“亥”の文字コード」は Shift_JIS において16進数の “88E5” だとの表現だ。
“亥”は文字。“=”も記号と説明されるが、文字に変わりない。逆の言い方をすれば、すべての文字は記号である。なぜなら、“文字”は図形により言語を表現する仕組みであるから。そして、文章においてそれ以上分割できない最小要素である。
皆さんはこのコラムで、“亥”という文字をパソコン上か、スマートデバイス上の画面で見ているはず。手書きではなく、機械上で表示されているものだ。“機械”は何らかの方法で文字を認識し、表示している(あえて言うまでもないが)。
コンピュータにおいて情報は全て数字で管理されているから、“文字”も同様に数字で置き換えられている。それが「文字コード」。
「文字コード」は文字(正確には文字概念)と数字の対応関係。
ちなみに、文字をコンピュータに分かる文字コードに変換することを“エンコード”、文字コードを人間に分かる文字にすることを“デコード”という。
ここで、少し噛み砕く。
「高」という文字は、「髙」(はしごだか)という字もある。どちらも「たか」と読み、「髙」が利用されるのは主に「髙橋」といった名前の場合だろう。
では、「高」と「髙」の文字コードは異なるか?
答えは・・異なる。それぞれ Shift_JIS において「高(0x8D82)」「髙(0xFBFC)」だ。

「高」や「髙」を字体という。
「字体」:図形文字の図形表現としての形状についての抽象的概念(ISO X 0213:2000)
「高」と「髙」は字体が違う。「土」と「士」も似ているが字体が違う。
しかし、「高」と「高」は、字体は違わず、字形が違う。
「字形」とは、同じ字体に対して表現が違うもの。コンピュータにおいてはフォントの差だ。「高」は“MS 明朝”、「高」は“HGP行書体”。
文字コードは字体に対するものであり、字形に対しては適用しない。
漢字は、苗字において「高橋」「髙橋」、「渡辺」「渡邉」「渡邊」、など、同じ字だが字体が違う“異体字”がある。これをコンピュータで制御しなければいけない。日本語は大変・・・・
・文字コードの歴史
「文字コード」という「セット」は1つではない。文字コードの歴史は、各地域が、そして世界で共通の体系を、どうやってルール化するかの歴史である。
「亥」は、Shift_JISで0x88E5だが、
Unicode:U+4EA5
UTF-8 :E4 Ba A5
である。また、住基ネットや戸籍統一番号など、個別のシステムによっては、それぞれのコードを持っている。
コンピュータによる表現での文字コードは、ASCII、EBCDEC、そしてShift_JIS、Unicode、UTF-8といったコード系が利用されてきた。少し、文字コードの流れについて触れたい。
・ASCII
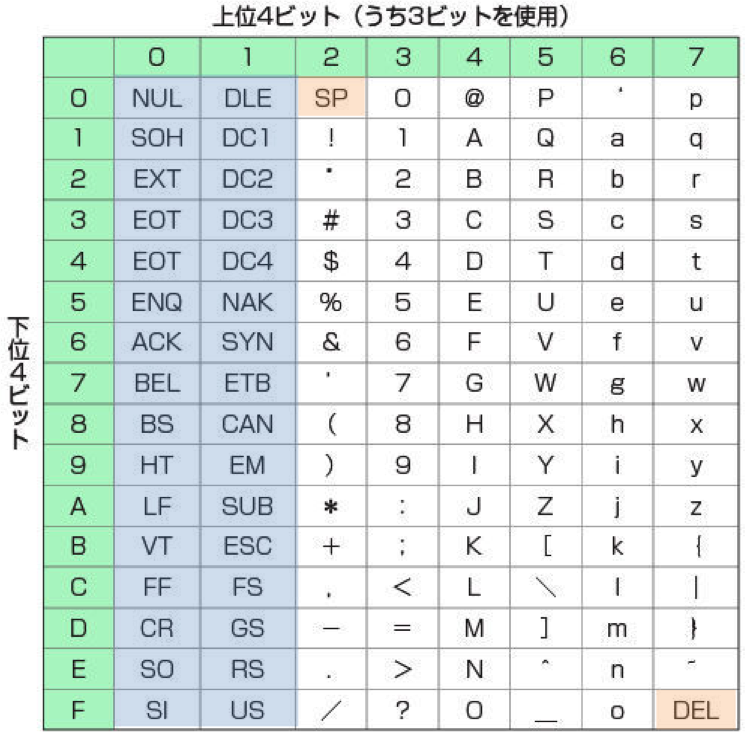
画像:ASCIIコード表
ASCIIはコンピュータで利用される文字コードのルーツと言っていいと思う。私が最初に文字コードを意識したのもASCIIだった。
ASCII(American Standard Code for Information Interchange)は、アメリカにおいて文字通信(テレタイプ)のために考えられたものだ。
7ビットで表現するので、128のコードを利用できる。
コード表を見ての通り、左2列の32文字が制御文字、96文字が図形文字であり、そのうち空白(0x20)と削除(0x7F)がある。
ASCIIはこれだけしか表現できない。図形文字は英数字と半角記号のみ。それでもルーツである。
制御文字は、機械を制御するためのもの。LF(0x0A)はLine Feedの略で、“改行”。
(改行コードの問題)
システム開発する方々は「改行ね」という感じだと思うが、今も改行は、
・Windows 0x0D0A
・UNIX 0x0A
・Mac 0x0A(バージョン9までは0x0D)
と、統一されていない。おかげで、プログラムにおいて常に注意しなければいけないものだ。早い段階でなんとかならなかったのかと思う。
ルーツであるASCIIだが、アルファベットであってもフランス語のウムラウトやアクセント記号(例:é)などがある。また、日本語だけでなく、世界の言語を考えれば7ビットでは全く足りない。ではどうするのか?という話になる。
なお、文字コードは大多数が合意し利用時にそれを遵守しなければ成り立たない。よって、それを規格として定義している機関、団体がある。
世界として代表的な団体が、
ISO(International Organization for Standardization:国際標準化機構)。
なぜ略称は“IOS”ではないのか?いくつかの定説があるが、ギリシャ語のISOS(等しい)からきている、ISOの方が発音しやすい、といったことのようだ。
【骨休め:アスキーアート】
アスキーアート(ASCII Art)というプレーンテキストを用いた絵がある。
タイプライター時代から活字をアート化するものはあったようだが、日本において注目されたのは、やはりインターネットが活用され始めたころの「2ちゃんねる」に代表される掲示板だろう。
著作権の関係でこれを選んだが、「ここまで書くか?」というアートがあり「すごい!」とともに「暇人か?」と思ったものだ。
「2ちゃんねる」を含む掲示板は、ネット上での人の繋がりという新たなコミュニケーションを生むとともに、個人を特定した誹謗中傷というネガティブな側面の最初であったと思う。しかし、“インターネットを楽しむ”点において「個が活躍する」という、インターネットの本質の始まりでもあった。
・ISO 646
ASCIIというアメリカの規格をISOが国際化したものが、ISO646。
ASCIIを他の国でも使えるようにするため、#、$、[、/、]などの記号部分を各国で入れ換えられるようにしている。共通なのは82文字。
・JIS X 0201
ISO646の日本版が JIS X 0201 である。
1969年の制定で、日本における最も古い文字コードだ。
最初は JIS C 6220 と言われており、俗称はANKコード。アルファベット(Alphabet)、数字(Numerical digit)、カタカナ(Katakana)という構成文字からの名前だ。キャリアのある方は「ANK」って懐かしい響きだと思います。
ISOはNGO(非政府機関)だが、JIS(Japan Industrial Standard:日本工業規格)は国家規格。なお、JIS規格は経済産業省配下のJISC(Japanese Industrial Standard Committee)による審議と主務大臣の認可を受け、JSA(Japanese Standard Association:日本規格協会)によって規格書が発行される。
JIS X 0201 は、ラテン文字用図形文字集合と片仮名用図形文字集合2つの文字集合からできている。そして、ラテン文字用図形集合は基本的にASCIIと同様だが、2文字だけ変えている(「\」(バックスラッシュ)を「\」(円記号)に、「~」(チルダ)を「‾」(オーバーライン)に。
余談:バックスラッシュを上記で表示するには、HTML上で英文フォントにする必要がある。まさに文字コードが円記号と同じであるためだ。
そして、ASCII同様に7ビットを使い、コード表を切り替える方式と8ビット全てを使う8ビット方式がある。コード表の切り替えには、SHIFT-IN(0x0F)、SHIFT-OUT(0x0E)を利用し制御する。SI/SO は、元々テレタイプで黒と赤のインクリボンを切り替えるために作られたものだ。
しかし、JIS X 0201 は所詮ANKであり、「日本語」には程遠い。
その後、非ISO646系としてISO2022系が規格された。この系の重要な拡張は2バイト以上の文字コードを扱える点だ。
・JIS X 0208
日本発で世界初の多バイト文字コード。
2バイトで1つの文字を表現し、日本語の漢字・ひらがな・全角カタカナを可能とした。6,879の図形文字を含んでいる。
・JIS X 0212
JIS X 0208では足りない文字を含めたもので、1990年に制定された。
・JIS X 0213
JIS X 0208 を拡張し、進化したもので、2000年に制定された JIS X 0213:2000 は JIS2000 と呼ばれる。そして、2004年改定のものはJIS2004。しかし、 JIS X 0212 との互換はない。
・EUC-JP
EUC(Extended UNIX Code)は名前の通り、UNIX用の文字コードである。
ISO2022準拠でAT&Tが考えたもの。-JPは、その日本語版である。
・ISO 2022-JP
最も多く使われたインターネット上の文字コードと言える。しかし、半角カナはない。
各文字コードについて詳細な情報まで書くとあまりにも細かすぎるし、だれてしまうでしょう。また、少し書き疲れ・・・
非ISO2022系として、いよいよ Shift_JIS や Unicode が登場するが、それは後編に持ち越したい。また、後編では“フォント”にも言及する。フォントは字形でありデザイン。デザイナーがいかにがんばっているかにも触れてみたい。
なお、前編の最後に・・・
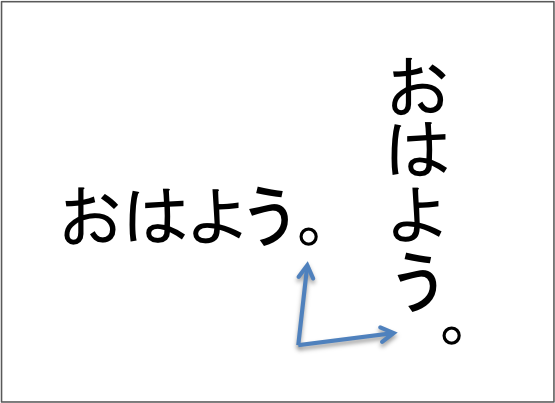
日本語は本来縦書きだ。では、横書きの日本語文字を縦に並べ替えればOKか?いや違う。
「。」の位置を見れば分かるように、横書き文字を単純に縦に並べ替えたら「。」の位置は左に寄ってしまう。これをフォントによって対応している。
また規格書には、例えば「亥 Shift_JIS:0x88E5」というように記されている。「亥」は違う字形として「亥」、「亥」・・・・と多数存在するが、代表的な字形を決めて書かねばならない。これを例字体、例示字体という。
参考文献
「文字コード『超』研究」(深沢千尋著) →660頁ほどの分厚い本だが、わかりやすく丁寧に詳細に説明されています(永井)
文責:永井一美
