コラム◆IT散歩/第10回:「“亥 = 0x88E5”、文字コードの世界」(中編)〜Font(ほんと)の話も〜
最初に新元号についての予想を・・・
過去247元号に対して使われた漢字は72文字。一番使われた漢字は「永」で29回、次が「元」と「天」で27回。昭和・平成は、よく使われた「和(19回)」、「平(12回)」と初である「昭」、「成」の組み合わせ。

私の苗字の一字である「永」と初の「愛」で、
「永愛(えいあい)」と予想。発音は「え」「あ」を強調せず、平らかに。“E”でM・T・S・Hとも重ならない。
“永遠の愛情”、ロマン(似合わないが)。
人、社会、世界に対して“愛”が重要なのだと思う。また、AI時代にかけて・・機械にも人の心を通わせたい。イチローの引退会見でも、貫いたことは「野球を愛したこと」と言っていましたね。
なお、中国の古典云々は調べていません。商標は簡易検索では問題なし。
(ネット情報では、同じ予想の人がいました)ただ「愛」の画数が多いので、ないかな。
さて、前回「亥(いのしし)」はなぜ十二支のビリなのか?から始まり、

・「“亥”の文字コード」は、Shift_JIS において16進数の“88E5”。
・コンピュータにおいて情報は全て数字で管理されている。
・“文字”も同様に数字で置き換えられている。それが「文字コード」。
・「文字コード」は文字(正確には文字概念)と数字の対応関係。
そして、「字体」と「字形」の話をして、「文字コードの歴史」をなぞる途中で終えていた。
今回の最初は、「Shift_JISの登場」から。
「文字コード」の話はつまらない、と思う方は「Fontの話」に飛んでください。
●文字コードの歴史(続き)
前編での最後に紹介したISO2022は、数多くの文字コード規格を包含する枠組みであった。
しかし問題があり、それを解決するものとして、非ISO2022系がある。
【ISO2022の問題】
・1バイトのうち7ビットしか使わず、制御文字を除くと94文字分のみであり、扱える文字数が少ない
・コード表の切り替えにより対応文字を増やすが、途中で参照コード表が分からなくなる
では・・・、Shift_JIS以降は、非ISO2022系。
・Shift_JIS
漢字を含む日本語表現のための文字コードとして、1982年に登場。
当時、マイクロソフト社により日本語表現時の標準として採用され、日本においては、パソコンでのデファクトスタンダードとして長く君臨してきた。
JIS X 0201コード表を基に、ローマ字/半角カナにて利用していない領域へJIS X 0208の漢字コードをシフト(ずらした)したことが名前の由来。
シフトしたことにより、1バイトの8ビット目(0x80~0x9F)を使うことでISO2022準拠ではなくなった。
【0x5C問題】
0x5CはJISローマ字において半角の円記号、ASCIIではバックスラッシュ。多くのプログラミング言語で、「\n」は「改行」として利用される。
「\」を文字として表示するなら「\\n」とコーディングしなければいけない。「\」が重要な役割を持っているため、「表示(0x955C 0x8EA6)」という文字の場合、「表」の後半コード(0x5C)が「\」と認識され、無視されることで文字化けを起こす。
文字コード(16進)の「0x5C」を意識する必要があるという、何とも悩ましい問題としてよく知られている。
言語によっては0x40、0x5Bで終わる漢字も問題となる。
・ISO 10646/Unicode
双方は、管理団体がそれぞれISO/Unicodeコンソーシアムと異なるが、一般的には同じコード系とみなされている。
方針は「ただ1つのコード表だけで世界の言語をまかなう」こと。
ISO 10646は、31ビットで約21.5億を表現する。そのうち21ビット分(0x0000~0x0FFF)をUnicodeでは利用していない。
世界中の文字に、個別のコードを与える。当初は、16ビット(65,536種類)あれば、全世界の全文字をコード化できる と考えていた。
ここで少し面倒な話を。図を参照しながら読んでください。
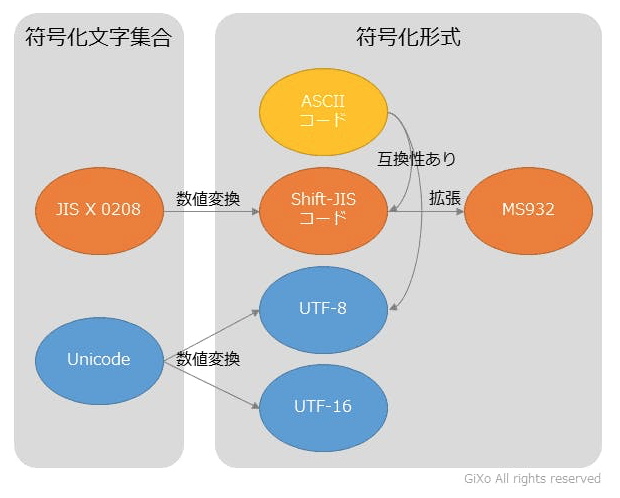
(文字符号化方式)
https://www.graffe.jp/blog/1278/
【Unicodeは1つではない(符号化文字集合と文字符号化方式)】
Shift_JISはShift_JIS(単一)。だが、UnicodeはUnicodeという単一ではない。
Unicodeは、
文字集合(符号化文字集合)・・・符号化する文字の集合。“ひらがな”も文字集合と言える。
文字コード系(文字符号化方式)・・・文字集合を符号化する際の方式
双方が区別されている。
「符号化文字集合」と「文字符号化方式」、なんだか分かりづらいが、日本語の文字集合であるJIS X 0208に対して、EUC-JP、Shift_JIS、ISO 2022-JPといった符号化方式があるのと同じ。
なので、Unicode(UTF-8)、Unicode(UTF-16)といった表現がされる。ここで「UCS」についての理解が必要。
【UCS(Universal multi-octet coded Character Set)】
複数のオクテット(8ビットのこと)を利用する全世界的な符号化文字集合。
UCS-2、UCS-4の「2」「4」は、それぞれ2オクテット(2バイト=16ビット)、4オクテット(4バイト=32ビット)を使って文字を表現する方式。
【UTF-8、UTF-16】
UTF(UCS/Unicode Transformation Format)は、UCSで定義された文字をどのように(バイト列)表現するかの方式。
UTF-16は、Unicode文字を常に16ビットで表す。「永」という文字は“U+6C38”。
UTF-8では“0x B6 B0 B8”。UTF-8は世界で最もポピュラーな文字コードといって良いかも知れない。プログラミングでは、「とりあえずUTF-8にしておけば」と言われるくらい。
ちなみに「永」のShift_JISは“0x8969”。UTF-8だけ、3バイト表現(0x B6 B0 B8)で違和感があるでしょう。エンコードの方法が他と違うのだが、それは調べてくださいm(__)m。
なお、Unicodeの話・情報は多い。また、機種依存文字・外字の話もあるが「文字コード」はここまでとしたい。
では、
●書体・フォント・フォントファミリー
「字体」と「字形」については説明した。では、「書体」「フォント」とは何か?また、フォントファミリーとは?
改めて、
「字体」:図形文字の図形表現としての形状についての抽象的概念(ISO X 0213:2000)
では「書体」は、
「一定の文字体系のもとにある文字について、それぞれの字体が一貫した特徴と独自の様式を備えた字形として、表現されているものをいう」
(Wikipediaより)と説明がある。説明文の中に、「字体」も「字形」も登場する。
私の解釈では、「字体」は抽象的な概念であるが「書体」は具体的。
【フォント】
「フォント」は「書体」と同義であるとも言えるが、コンピュータや印刷など、人とのインタフェースに利用するための「より具体的な書体」と捉えている。
もっと言えば、英字の「A」は文字コード(ASCII)で「0x41」。では、「A」をディスプレイ装置に表示するにはどうするか。表示のためのデータが「フォント」である。
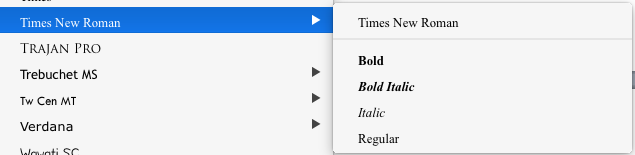
WORDやExcelで文字を入力するとき、様々なフォントを選べる。「Times New Roman」には、Bold・Bold Italic・Italic・Regularと4種類がある。
「フォントファミリー」はフォントのひとまとまりであり、同じデザイン。
ここで、おや?と思う方もいるかも知れない。WORDなどのOffice製品には「B(太字)」「I(斜体)」の機能がある。この“機能”とフォントファミリーのBoldやItalicとの関係は何か。

簡単に言えば、フォントが用意されているBoldやItalicはデザイナーがデザインして作られたもの。WORDなどでの“機能”は、各フォントファミリーでBOLD/Italicが用意されていれば、自動で切り替えを行ってくれている。
一方、フォントがない場合は擬似的に作っている。ゴシックの場合は、元の文字をずらしてかぶせ擬似的に太字にしている。
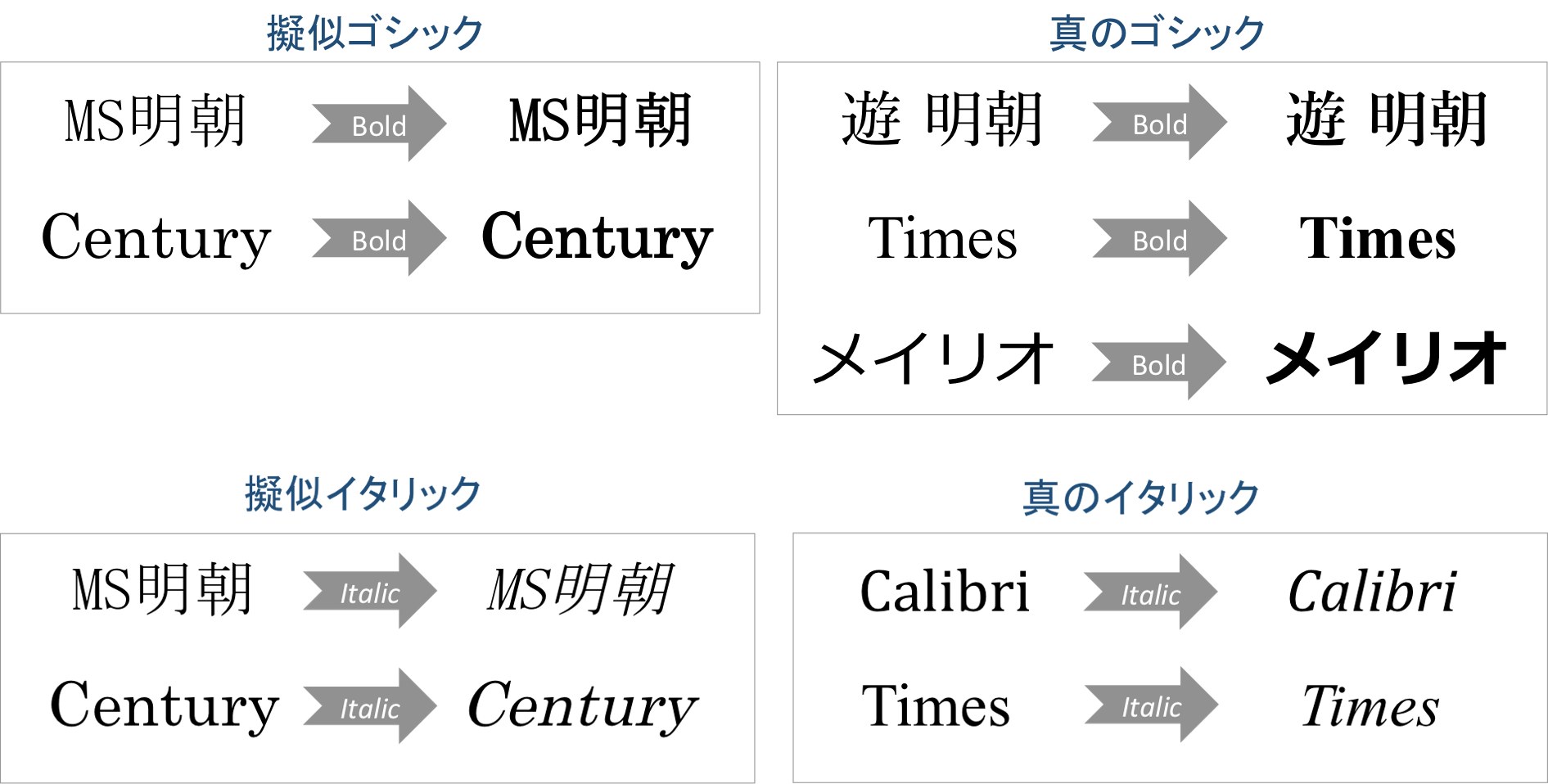
「真のゴシック」の“e”や“s”を見ると、擬似はそれぞれの線が単に太くなっているが、「真」はデザインされたものだと分かる。また、MS明朝と遊明朝を比べると、MS明朝は少しにじんだ感じがする。
イタリックの場合は、より顕著だ。「真のイタリック」での“a”や“e”は形状が全く異なる。なお、和文フォントにはそもそも斜体フォントがない。本来、日本語においては斜体を用いない。デザインの本では、和文での斜体は控えた方が良いとの助言もある。
●一休み
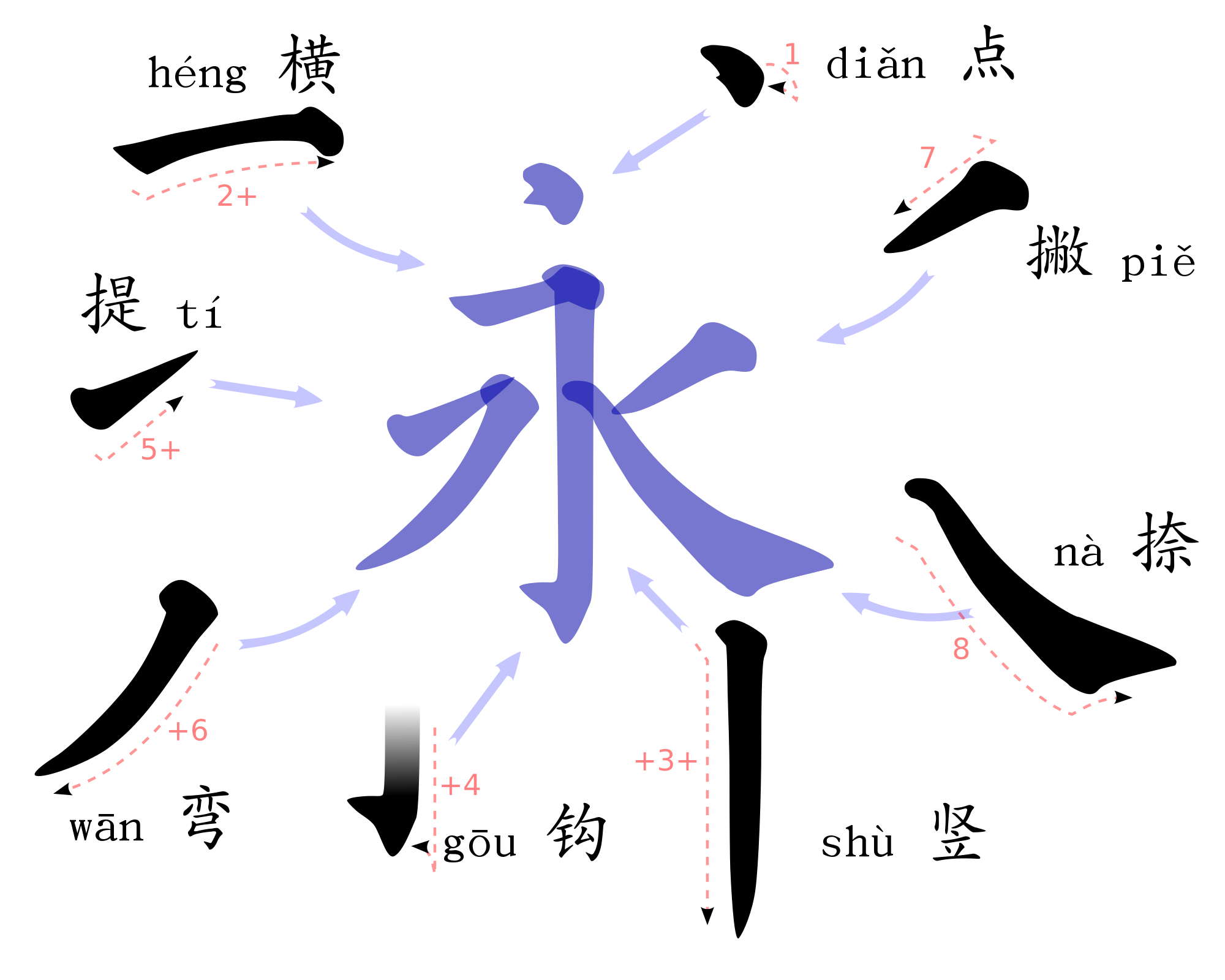
「永字八法」:「永」は書法に必要な8つの基礎点画が全て含まれているとの意味。
図は「筆画」での表現だが、下記の字で説明されているものが多い。
1:側(そく) 2:勒(ろく) 3:努(ど) 4:趯(てき)
5:策(さく) 6:掠(りゃく) 7:琢(たく) 8:磔(たく)
小さいころから何度書いたか分からない「永」の字。
しかし、字はちっともうまくならない・・・
ちなみに、「4:趯」での「はね」を使わないので、「はねないといけないでしょ!」とよく言われます。
【ビットマップフォントとアウトラインフォント】
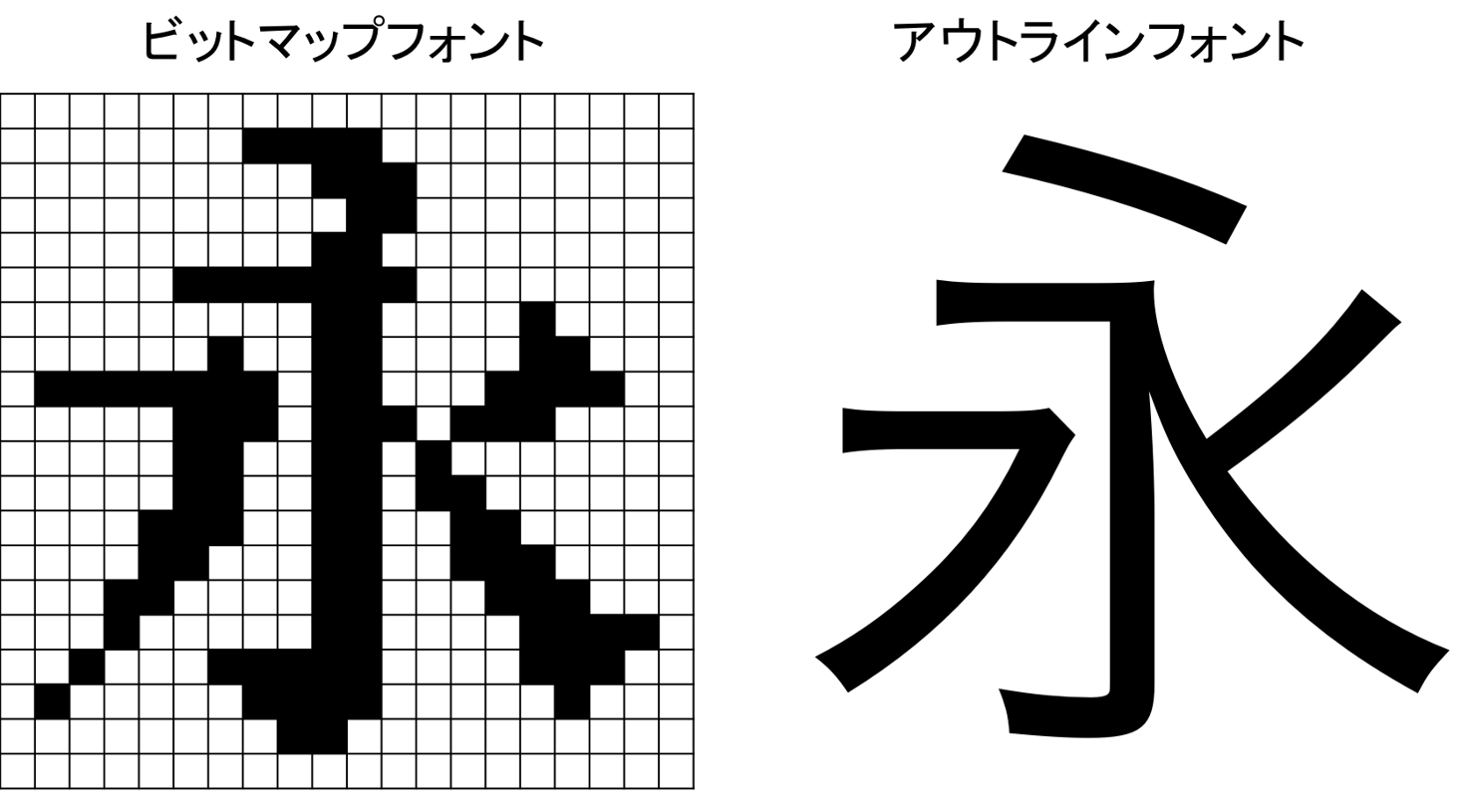
現在のフォントは、そのほとんどが「アウトラインフォント」と言われる種類。だが、PC黎明期では「ビットマップフォント」がよく使われていた。
図のビットマップはドット数が少なく極端だが、文字の拡大によりギザギザになってしまうことは知られている通り。また、コンピュータにおける情報量も多い。
ちなみに図の「アウトラインフォント」は「ヒラギノ角ゴ Pro W3」。
「W3」の「W(ウエイト)」およびアウトラインフォントの仕組みは改めて書きたい。
・・・図のビットマップフォント「永」は自分で作成。
作成していると、「この部分を黒にすれば斜めやカーブが表現できるな」と、デザインと呼べるほどではないが、なかなか楽しい作業でした。
なお、ビットマップファイルをコンピュータで処理するにあたり、内部構造に興味を持ったので、少し(ヘッダー部のみ)覗いてみた。 (念のため、罫線なしとして保存したファイルで確認)
数字の羅列部分が、ビットマップファイルのヘッダー部ダンプ情報。16進数で「0x 42 4D」で始まっている。
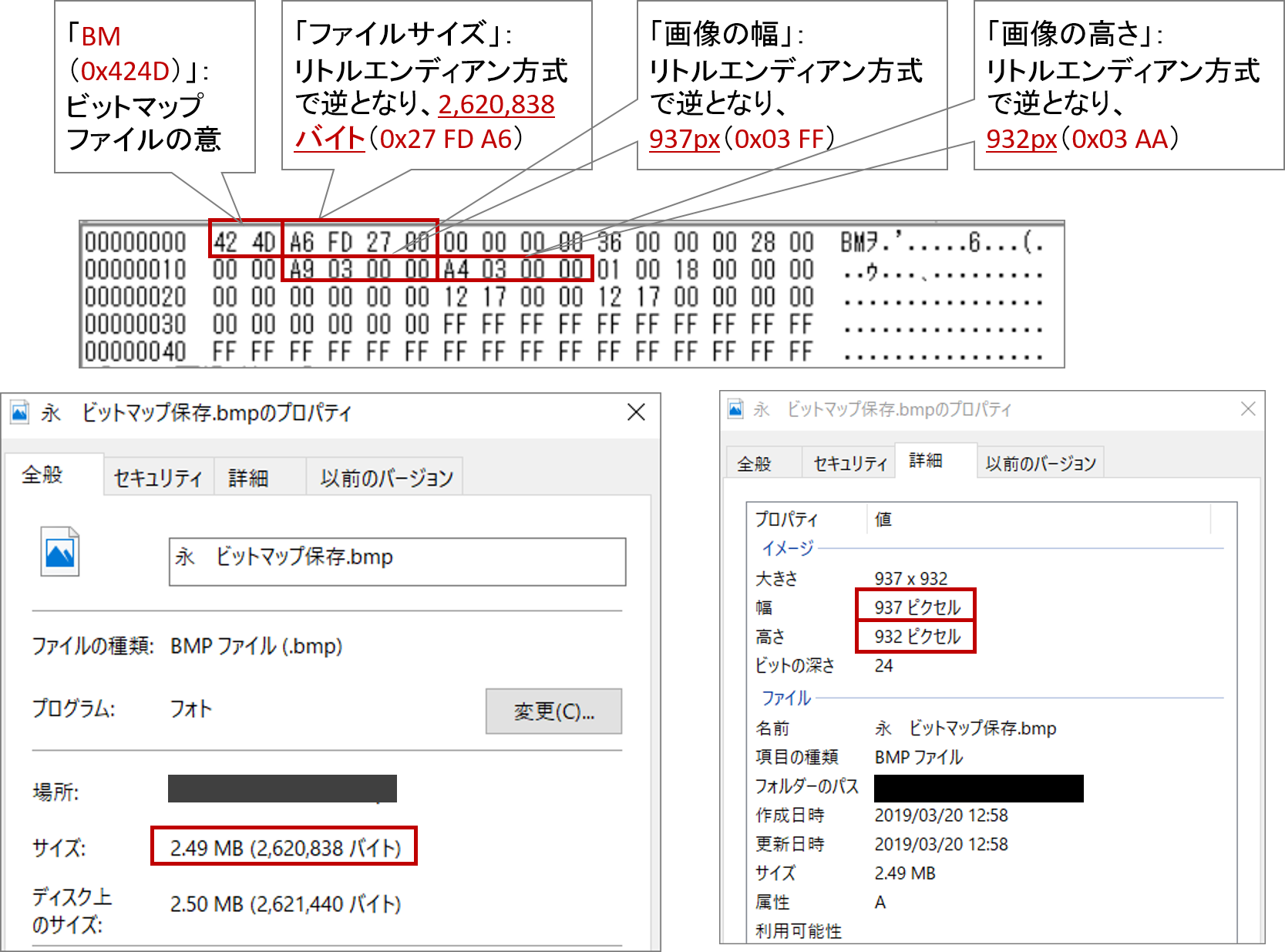
プロパティ
・0~1バイト
画像フォーマット種類:BM(0x 42 4D)としてビットマップを意味
・2~5バイト
ファイルサイズ:2,620,838バイト(0x 00 27 FD A6)
図の下左、プロパティの「サイズ」と一致
・18~21バイト
画像の幅:937ピクセル(0x 00 00 03 A9)
図の下右、プロパティ詳細の「幅」と一致
・22~25バイト
画像の高さ:932ピクセル
図の下右、プロパティ詳細の「高さ」と一致
他の情報は端折るが、データ部は「位置と色」が基本となるであろうことは分かると思う。
「永」のビットマップは2.49MB(2,620,838バイト)もの容量になっている。一方、アウトラインフォントである「永」をPNGファイルで保存したが、容量は23.1KB(23,745バイト)でしかなかった。
習字において、文字には様々な個性が現れる。「フォント」も“文字のデザイン”。“デザイン”は感情を揺さぶる。
今回、芸術的な面まで進めたかったのだが、思いのほかボリュームが増えてしまった。そのため「後編」ではなく「中編」とし、次回を「後編」としたい。
次回はFontの構成やデザイン面、および「新元号」が決定しているので「元号」について触れてみたい。
参考文献
「文字コード『超』研究」(深沢千尋著)/発行所 ラトラズ
「伝わるデザインの基本」(高橋佑磨、片山なつ)/発行所 技術評論社
文責:永井一美
